直近開催のScrum Alliance認定スクラムマスター研修のご案内
オープンソースの全文検索エンジンFessを試してみた
みなさんこんにちは。@ryuzeeです。
このWebサイト、昔はWordpressを使っていたのですが、本体やプラグインのメンテナンスを頻繁にやらなきゃいけなくて面倒なのと性能面などで辛くなって、その後Ruby製の静的サイトジェネレータであるMiddlemanに変更し、その後ビルドの遅さに耐えられなくなってGo言語で作られているHugoに置き換わっています。
静的コンテンツになればAmazon S3などで運用できるので非常に楽なのですが、一方でサイト内を検索したい場合は別の解決策の用意が必要になります。Googleの検索を埋め込んでももちろん良いのですが、調査の一環として、今回はオープンソースの全文検索エンジンFessを試してみました。
Fessの特徴
公式サイトで詳細に紹介されていますが、主な特徴として以下のようなものが挙げられます。
- 5分で簡単に構築可能
- Apache ライセンス
- Java 1.8を利用しておりOSには依存しない
- Web以外に共有フォルダなどもクロールできる
- クローリングの設定など必要な設定はすべてGUI上でできる
- Elasticsearchを検索エンジンとして利用している(内包しているので別途インストールの必要はない)
インストール
Java 1.8以上の環境であれば環境を選ばないということですが、使い慣れているUbuntu 14.04に構築します。なお、Ubuntu16系であればデフォルトでopenjdk-8が利用できるようになっているので多少手順は減ります。
必要なパッケージのインストール
ここでは、Fessを動かすのに必要な、Java 1.8の環境、Proxyとしてapache2、Fessを常時起動しておくためのSupervisorなどをインストールします。
sudo apt-get update
sudo apt-get install -y apt-file
sudo apt-file update
sudo apt-get install -y software-properties-common
sudo add-apt-repository ppa:openjdk-r/ppa
sudo apt-get update
sudo apt-get install -y language-pack-ja
sudo apt-get install -y unzip
sudo apt-get install -y openjdk-8-jdk
sudo apt-get install -y apache2 supervisor
sudo a2enmod proxy proxy_http proxy_html xml2enc
sudo update-alternatives --set java /usr/lib/jvm/java-8-openjdk-amd64/jre/bin/javaFess本体の配置
Fess本体はどこに配置しても構いません。今回の場合は/opt/fessに配置します。
wget https://github.com/codelibs/fess/releases/download/fess-10.1.1/fess-10.1.1.zip
unzip fess-10.1.1.zip
sudo mv fess-10.1.1 /opt/
sudo ln -s /opt/fess-10.1.1 /opt/fessここで、/opt/fess/bin/fessを実行すれば起動しますが、一旦先に進めます。
Supervisorの設定
SupervisorでFessをデーモン化します。
/etc/supervisor/conf.d 以下にfess.confなどの名前で以下のような中身のファイルを作成します。なおuserの箇所はfessディレクトリの持ち主にあわせてください。Vagrantの場合は、vagrantで、AWSの場合だとubuntuになるはずです。
[supervisord]
nodaemon=false
[program:fess]
command=/opt/fess/bin/fess
user=vagrant
autostart=true
autorestart=true
stdout_logfile=/var/log/fess.log
redirect_stderr=trueできあがったら、Supervisorを念の為再起動します。
sudo service supervisor restartこれでFessが自動で起動しているはずです。
Apacheの設定
この時点ではFessは8080ポートでListenしているので80ポートでアクセスできるように手前にApacheなどのHTTP Serverをかまします。/etc/apache2/sites-enabled にある 000-default.conf を以下のように修正します。
<VirtualHost *:80>
#ServerName www.example.com
DocumentRoot /var/www/html
ErrorLog ${APACHE_LOG_DIR}/fess_error.log
CustomLog ${APACHE_LOG_DIR}/fess_access.log combined
<Location />
ProxyPass http://localhost:8080/
</Location>
</VirtualHost>ここまでできたらApache2を再起動して、ブラウザでアクセスしてみます。なお、現時点ではなにもインデックスされていないので検索してもなんの結果もでません。

インデックス関連の設定
次に管理画面にログインしましょう。右上のリンクからログインします。初期値はユーザーIDとパスワードともにadminです。 ログインが終わったら、いろいろな設定をする前に、左メニューの「ユーザー」の箇所にアクセスしてパスワードを変更しておきます。
そしてクローラの設定をするために、左メニューのクローラからウェブを選択して、新規に設定をおこないます。

設定する項目は順に以下のようになります。
- 名前:このクロールの設定の名前。自分で区別が付く名前を好きにつけます
- URL:起点となるURL
- クロール対象とするURL:起点からページを辿っていくときに対象にするURLを指定
- クロール対象から除外するURL:タグ別のページなどクロールしなくてもよいページを指定
- 検索対象とするURL:画面から検索したときに対象とするURLを正規表現で指定
- 検索対象から除外するURL:検索結果に出さないURLを正規表現で指定
- 設定パラメータ:クロールする際の設定値を渡せる。たとえば field.xpath.default.content=//*[contains(@class,‘article_body’)] のように指定すると、検索対象を特定の要素に限定できる
- 深さ:何階層たどっていくかを指定
- 最大アクセス数:1度のクローリングで何ページまでクロールするかを指定
- スレッド数:クローラの同時並列数を指定
- 間隔:1回のページ取得の間にどれくらい待ち時間を入れるか指定
- ブースト値:クローリングで取得した結果の重み付け。値が大きければ検索結果として上位にでるようになる
ここまで設定が終わったら実行してみます。通常Webクローラは毎日0時に動くことになっていますが、システム→スケジューラの順にたどると、Default Crawlerの設定がありますので、ここで「今すぐ開始」をクリックして実行します。どのくらいの時間がかかるかはクロール対象のページ数などによって変わります。

画面デザインの修正
Fess自体はテンプレートにBootstrapが使われているので、レスポンシブルにも対応していますし、CSSなどを用意すれば簡単にデザインを変更できます。 たとえばヘッダーを変更したければ「システム」→「ページのデザイン」とたどり、「ページファイルの表示」の箇所から「ヘッダー」を選択して編集ボタンをクリックして編集します。

同じように他のパーツを編集したり、ロゴイメージをアップロードして差し替えるといったことが可能です。
ここまでやれば以下のような感じになります。
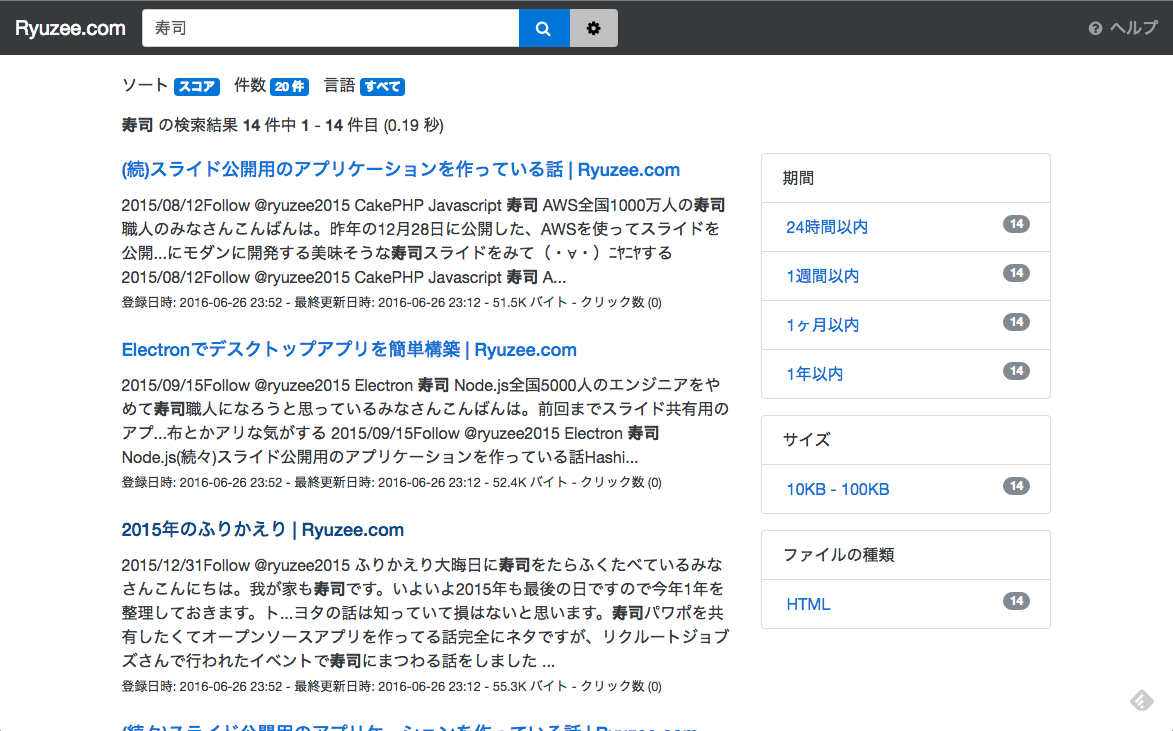
まとめ
5分で使えるという謳い文句どおりにすぐ使える全文検索でした。オフィスドキュメントやファイルサーバなんかにも対応しているのでWebサイトの検索にかぎらず色々使いどころがありそうです。







































